



Hello Reader!
If you are a programmer worth your salt, you must have heard about Cron. Some people love cron jobs, some hate them, yet most have universally used it. If you haven't used cron jobs yet, you might use it at least once in your professional career.
Cron jobs are considered to be the backbone of a functional server system in every sense of the word. With its core functions mainly revolving around scheduling tasks, rest assured that you cannot run your server system without cron jobs. I can surely relate this to my personal experience.
Recently, while scaling our infrastructures, we faced the challenge of running Crons on multiple servers and avoiding re-runs of the same job.
In this article, we will first get familiar with the cron, and then I will try and explain the problem we had while working with Crons and how we solved it?
Introduction
Cron is a time-based job scheduler in Unix-like computer operating systems. It schedules commands to run at certain times or dates, normally running them at a specified time on a routine basis. Now, before rushing into our implementation, we will first try to analyze the basic principles of crons and their standard implementations. Then we will see how crons can be extended to work seamlessly in a large distributed environment.
What is a Cron?
Crons were designed to run commands at a predefined time as provided while defining a cron. Cron has been popular for decades because it's easy to use and available everywhere, but it has a downside of high maintainability, and debugging at times can be a real headache. Cron executes various types of jobs, including periodic data analysis. The most common time specification format is called "crontab." This format supports simple intervals (e.g., "once a day at noon" or "every hour on the hour"). However, complex intervals, such as "every Sunday, which is also the 30th day of the month," can also be configured.
Example: Whatsapp has a backup feature, we can choose a custom time, and Whatsapp shall automatically take backup of the chats at the defined time.
Crons at Large Scale
It is a completely different aspect to draw a system design for a single machine, and while moving single machines toward large-scale deployments, a novel thought process is required to make crons work.
Problem at Hand?
We wanted to run multiple cron jobs on multiple servers to distribute load and didn't want to repeat the execution. There are existing utilities like dkron , which gives this functionality, but it would have been an additional burden on our team to manage another utility.
System Design and Initial Idea
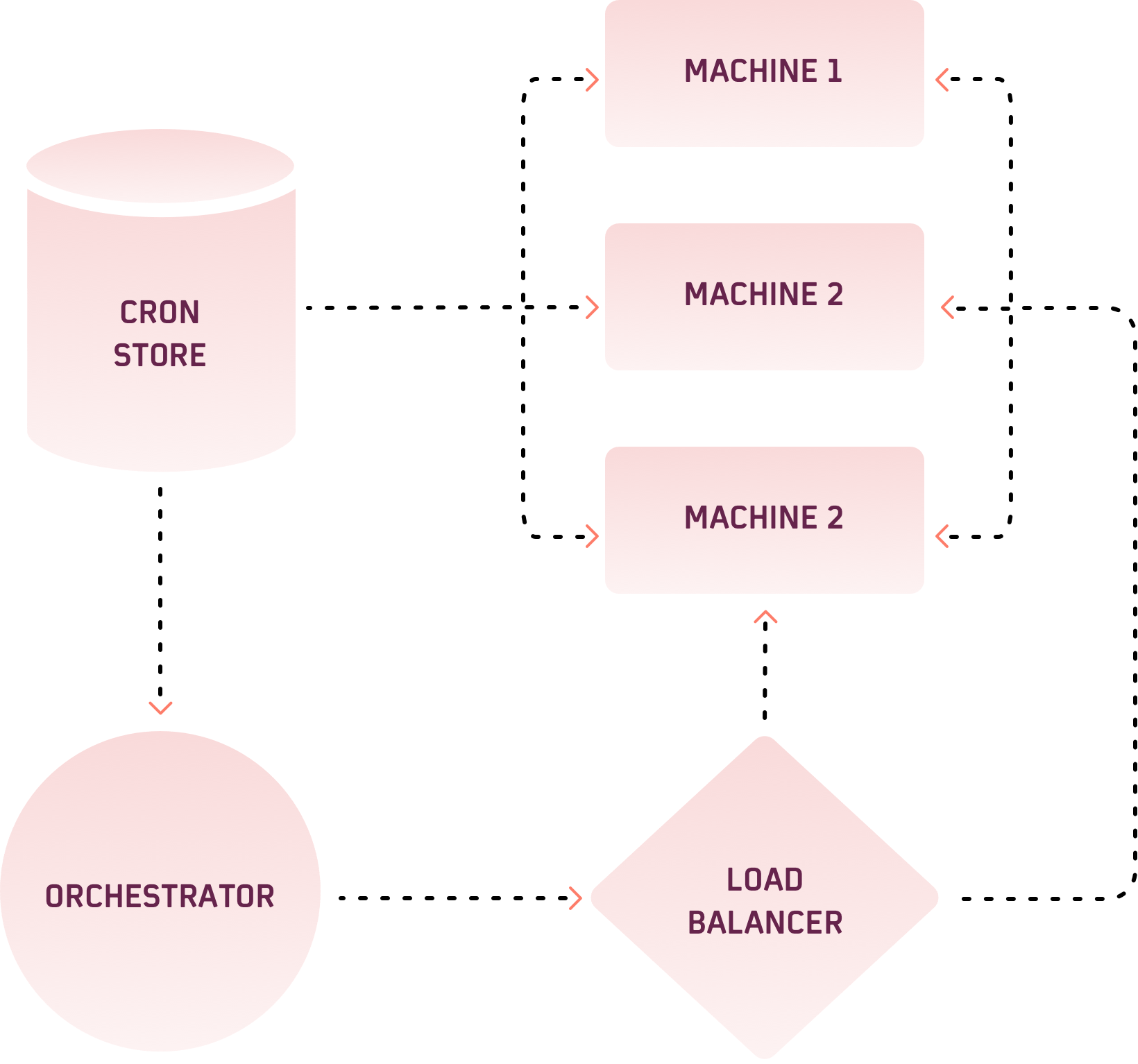
Before delving further, it's essential to describe all the components of this system:-
Cron Store:- It is a store for all the cron jobs that we have. Cron jobs can be added externally to it. It has a complete configuration to run a job, like its full Http Address, the frequency of the cron. As this store is external to the Executor, we can change the configuration of a job(like its frequency).
Executor:- It is a machine on which the code corresponding to the job exists, and the job also runs on this machine.
Orchestrator:- It is the brain of the system that is responsible for triggering the API calls corresponding to a cron.
Load Balancer:- Load Balancer is for simple methodical and efficient distribution of traffic across multiple servers of Executor.
This idea was to have a stateless cron executor, basically, a machine that will execute a piece of code at regular intervals, which will be triggered externally. The Executor won't know if a particular code piece is a cron or not. As the configuration of a cron job was only on cron store, so our executors were devoid of the state of a cron. The Logic of a cron job is exposed through an API endpoint. (we used RPC here).
Grey Matter
At regular intervals (HCF of all the cron intervals in the cron store), the orchestrator will pick all the due cron jobs from the cron store and hit the corresponding endpoints of executors. As all the requests went through a Load Balancer, so those requests were smartly divided amongst our available executors avoiding repetition of cron executions. The presence of Load Balancer also gave us the additional support of health checks on our machines for their upkeep.
Orchestrator performs a very repetitive job on Cron Store, and Cron Store can be ever-increasing, so relying on an AWS Lambda instance was a good choice(for being server-less and auto-scalable on demand), since our crons were quite limited in number hence for cost benefits EKS pod was a natural choice.
Way Ahead
Although the orchestrator that this system has is optimum for the execution of crons, the one thing it misses is a priority assignment to crons. Cron store can also store the priorities of these cron jobs, and while fetching due crons, they can be ordered by their corresponding priorities. If Redis is used as a cron store, we can use sorted sets to maintain priorities; hence, fetching due jobs will be easier.
That's all from me. Hope you liked this article.
If you want to explore more on this topic, please go through the following link: