

Continuous Deployment using Ansible-Pull
A Pull-based Model To Deploy Code With Ansible



At LambdaTest, there is a massive scale-in of dedicated machines (inventory) on which Continuous Deployment needs to be performed on a regular basis. The deployment usually done earlier via webhooks to trigger the CD tool to begin the deployment process with a push-based mechanism. The deployment process worked without any issues when we had an inventory less than 500 but after we scaled beyond that, this method started to fail due to below challenges:
- If push-based deployments are poorly implemented, it resulted in an infrastructural drift in the system. Moreover, it kept the engineering team busy with different functionality issues.
- The DevOps (or Infra) operations team had to maintain the untagged assets records in sheets, which ended up to be super cumbersome.
- At scale, when performing change management of the system, certain servers wouldn't respond which can eventually lead to a failure in the deployment process.
When looking for a potential solution, we came across ansible-pull which was apt for solving challenges in our current use-case. With this, we avoided the need to do usual push implementation via Ansible Playbooks.
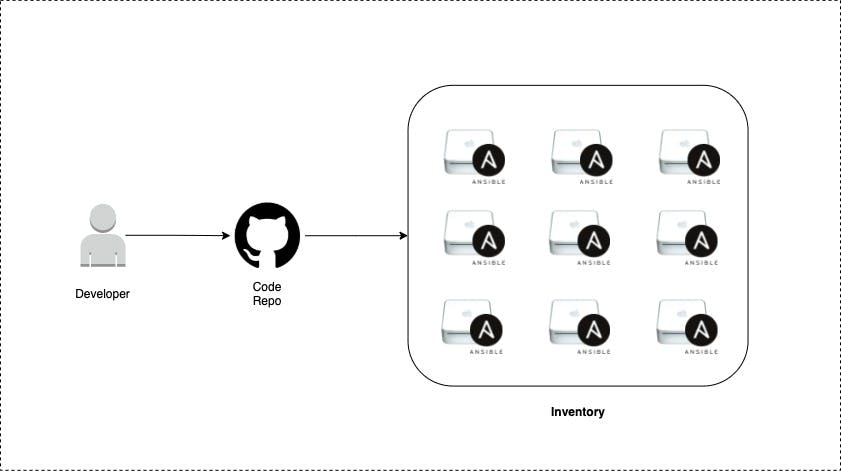
Let us deep-dive into the essential aspects of ansible-pull and how we leveraged it for Continuous Deployment at LambdaTest.
What Is an Ansible Pull?
In an Ansible pull-based approach, the servers pull the latest Ansible code from a central repository and run the tasks accordingly. The system admin no longer has to run any manual tasks :)
Official doc for ansible-pull module is available here
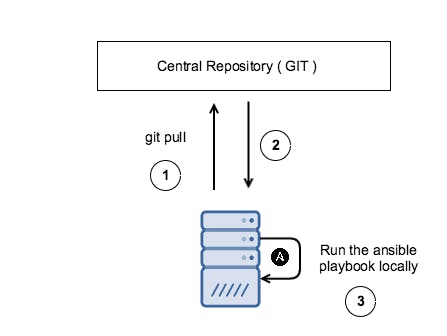
How to pull the latest Ansible code?
The remote server will pull the latest Ansible code from central repositories like Git to the local machine. The inventory file will typically have the IP as 127.0.0.1. The Ansible code is normally pulled through an option -U which is passed with remote repository URL while executing ansible playbook. This execution part is set in a cron job that runs at a specific time frame (e.g. every day at midnight).
Deep dive into quickinstall.sh
A shell script for setting-up the target machine for the ansible-pull. Command to download the script:
curl -H 'Cache-Control: no-cache' -H 'Accept: application/vnd.github.v3.raw' -L 'https://raw.githubusercontent.com/<path>/quickinstall.sh' > quickinstall.sh
This is a one time execution command which need to be executed to setup the machine. The downloaded file consists installation of git, python, pip, ansible.
quickinstall.sh file
#!/bin/bash
# Install this setup locally, with default settings.
set -x
set -e
PATH=/usr/local/bin:$PATH
if [[ -f /usr/bin/apt-get ]]
then
sudo apt-get update
fi
if ! which git
then
if [[ -f /usr/local/bin/brew ]]
then
/usr/local/bin/brew install git
fi
if [[ -f /usr/bin/apt-get ]]
then
sudo apt-get install -y git
fi
fi
if ! which ansible
then
if [[ -f /usr/local/bin/brew ]]
then
/usr/local/bin/brew install ansible
fi
if [[ -f /usr/bin/apt-get ]]
then
sudo apt-get install -y python3-pip
sudo pip3 install ansible
fi
fi
mkdir -p /Users/User/ansible/
Ansible Playbook Structure
The code structure is pretty straightforward. This is how the ansible-pull job is set up:
ansible-pull-deployment/
.
├── README.md
└── playbook/
└── main.yml
└── roles
├── binary_deployment/
├── self_healing/
└── configure/
playbook/main.yml file
The playbook/main.yml file is where things get super interesting. If you have been using Ansible, it should be fairly straightforward to make it work for your project. It’s a basic playbook which deploy the application, setup and configure the things on machine. There are roles for specific tasks to be performed:
---
- hosts: localhost
gather_facts: yes
roles:
- role: binary_deployment
- role: self_healing
- role: configure
CronTab for Scheduling
This is the easy part, all you need to do is adding the following command as a cronjob to the system:
0 3 * * * /usr/local/bin/ansible-pull -U https://github.com/<link-to-github-code>.git -C master -d /Users/User/ansible/ -i localhost, playbook/main.yml
- This cron job will execute every day at 3 AM.
- The next part of the command is the full path to the ansible-pull command which fetches the updated code from the repo URL provided by -U option and -d to save the playbook code on the local drive.
- Finally, the command includes a hosts file that the playbook will run against.
Conclusion
The pull-based deployment strategy of Ansible helped LambdaTest in reducing infrastructural drifts in the system, with scalability.